Notes of Dense Trajectories
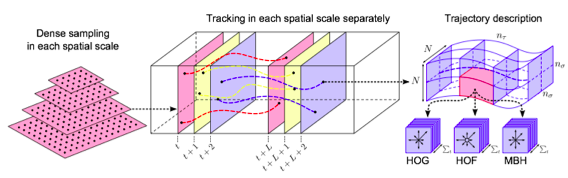
- densely sample feature points in each frame
- track points in the video based on optical flow.
- compute multiple descriptors along the trajectories of feature points to capture shape, appearance and motion information.
-
Dense Sampling
- Sampling step size \( W=5 \) pixels
- # spatial scales ≤ 8
- Spatial scale increase: \( 1 / \sqrt{2} \)
- Removing points in homogeneous areas: $$ T=0.001 \times \max_{i \in l}\min(\lambda_{i}^{1},\lambda_{i}^{2}) $$, where \( (\lambda_{i}^{1},\lambda_{i}^{2}) \) are eigenvalues of point \(i\) in image \(I\) (the auto-correlation matrix).
-
Descriptors
-
Trajectory shape descriptor(TR):
-
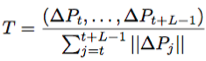
where L is the length of trajectory, and the displacement vectors
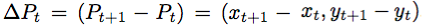
- HOG – static appearance information
- HOF – local motion information
- MBH – motion descriptor for trajectories
-
Format of DTF features
The format of the computed features
The features are computed one by one, and each one in a single line, with the following format:
frameNum mean_x mean_y var_x var_y length scale x_pos y_pos t_pos Trajectory HOG HOF MBHx MBHy
The first 10 elements are information about the trajectory:
- frameNum: The trajectory ends on which frame
- mean_x: The mean value of the x coordinates of the trajectory
- mean_y: The mean value of the y coordinates of the trajectory
- var_x: The variance of the x coordinates of the trajectory
- var_y: The variance of the y coordinates of the trajectory
- length: The length of the trajectory
- scale: The trajectory is computed on which scale
- x_pos: The normalized x position w.r.t. the video (0~0.999), for spatio-temporal pyramid
- y_pos: The normalized y position w.r.t. the video (0~0.999), for spatio-temporal pyramid
- t_pos: The normalized t position w.r.t. the video (0~0.999), for spatio-temporal pyramid
The following element are five descriptors concatenated one by one:
- Trajectory: 2x[trajectory length] (default 30 dimension)
- HOG: 8x[spatial cells]x[spatial cells]x[temporal cells] (default 96 dimension)
- HOF: 9x[spatial cells]x[spatial cells]x[temporal cells] (default 108 dimension)
- MBHx: 8x[spatial cells]x[spatial cells]x[temporal cells] (default 96 dimension)
- MBHy: 8x[spatial cells]x[spatial cells]x[temporal cells] (default 96 dimension)
-
Improved Dense Trajectories
- Explicit camera motion estimation
- Assumption: two consecutive frames are related by a homography.
- Match feature points between frames using SURF descriptors and dense optical flow
- Removing inconsistent matches due to humans: use a human detector to remove matches from human regions (computation expensive)
- Estimate a homography with RANSAC with these matches
References:
-
H Wang, C Schmid, Action recognition with improved trajectories, ICCV 2013
-
H Wang, A Kläser, C Schmid, CL Liu, Dense trajectories and motion boundary descriptors for action recognition, International Journal of Computer Vision, May 2013, Volume 103, Issue 1, pp 60-79