This post explains how to implment a ring buffer that can be shared between multiple processes. For the simplicity and efficiency, shared memory is used to store the ring buffer. A read/write lock is also developed to sync the inter-process buffer read/write operations. The source code can be found on my GitHub channel.
pthread In Multiprocessing
pthread mutex and condition also can be used for inter-process synchronization. There are two process-shared attribtues in pthread:
-
PTHREAD_PROCESS_PRIVATEis the default attribute, which only operates upon threads created within the same process that initialized the mutex/condition. -
PTHREAD_PROCESS_SHAREDpermits a mutex/condition to be used by any thread that has access to the memory, even if the mutex/condition is in memory that’s shared by multiple processes.
The attribute can be set by function pthread_mutexattr_setpshared or pthread_condattr_setpshared respectively. The following code demonstrates how to use pthread interprocess mutex. The same applies to a pthread condition variable.
#include <pthread.h>
...
pthread_mutexattr_t attr;
/* init mutex attribute */
pthread_mutexattr_init(&attr);
pthread_mutexattr_setpshared(&attr, PTHREAD_PROCESS_SHARED);
/* init mutex */
pthread_mutex_init(&shm_mutex, &attr);
/* use mutex */
pthread_mutex_lock(&shm_mutex);
// do something
pthread_mutex_unlock(&shm_mutex);
/* clean up */
pthread_mutex_destroy(&shm_mutex);
pthread_mutexattr_destroy(&attr);
Shared Memory
There are different shared memory implementations and APIs. In this post, the POSIX shared memory APIs are used. When using these APIs, pay attention to following pitfalls.
-
The first argument of
shm_open()points to the name of the shared memory. At least in MAC OS X or Linux, it must be a path beginning with “/”, and no sub-dir is allowed. In Linux, theshm_open()creates a new node under/dev/shm/with the specified name. -
The default shared memory size after created by
shm_open()is implementation-defined. So better to callftruncate()to define the size of shared memory before mapping it. -
ftruncate()truncates the given file to the sepficied length. This means that this function may remove the extra data, or increase the size of shared memory. And if the size is increases, the extented area will be initialized to 0. -
Some flags of
shm_open()ormmap()may not be supported in all platforms, e.g.O_TRUNC.
/* Create shared memory object and set its size */
fd = shm_open("/myregion", O_CREAT | O_RDWR, S_IRUSR | S_IWUSR);
if (fd == -1)
/* Handle error */;
/* Truncate memory size */
if (ftruncate(fd, shm_len) == -1)
/* Handle error */;
/* Map shared memory object */
void * rptr = mmap(NULL, shm_len, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
if (rptr == MAP_FAILED)
/* Handle error */;
/* Now we can refer to mapped region using fields of rptr;
for example, rptr->len */
...
/* Unmap shared memory */
munmap(rptr, shm_len);
/* Destroy shared memory */
shm_unlink("/myregion");
Use C++ Class In Shared Memory
Like C struct, C++ class can also be stored in the shared memory, but you only can map the shared memory object to Plain Old Data(POD) class.
“A POD class is a class that is both trivial (can only be statically initialized) and standard-layout (has a simple data structure), and thus is mostly restricted to the characteristics of a class that are compatible with those of a C data structure declared with
structorunionin that language”.
This means that the class cannot contain any user-defined constructors, desctructors, copy assignment operator, non-static data members or virtual member functions.
C++11 provides std::is_pod to check for POD type, but this check is based on the C++11 criteria(much relaxed compared to C++98).
Ring Buffer
A ring(or circular) buffer is a fixed-size buffer, which can overwrite new data to the beginning of the buffer when the buffer is full. The ring buffer can be simply implemented with an array and two indices - one index points the beginning of the buffer, and the other index denotes the end of the buffer.
If the buffer is empty, the begin index equals to the end index(for simplicity, set them to 0). When new data comes, push it to the entry of the end index, and increase the end index. At this moment, if the begin index equals to the end index, then increase the begin index, too. All of the index operations must modulo the size of the array, in case of buffer overflow.
The pseudo code for adding new data is:
// A - ring buffer array
// _begin - start index of the ring buffer
// _end - end index of the ring buffer
// _capacity - size of the ring buffer
A[_end] = data;
_end = (_end + 1) % _capacity;
if (_end == _begin)
_begin = (_begin + 1) % _capacity;
ShmRingBuffer Library
The source code of this library can be found on my GitHub channel. The memory layout of class template ShmRingBuffer is shown in the following figure.
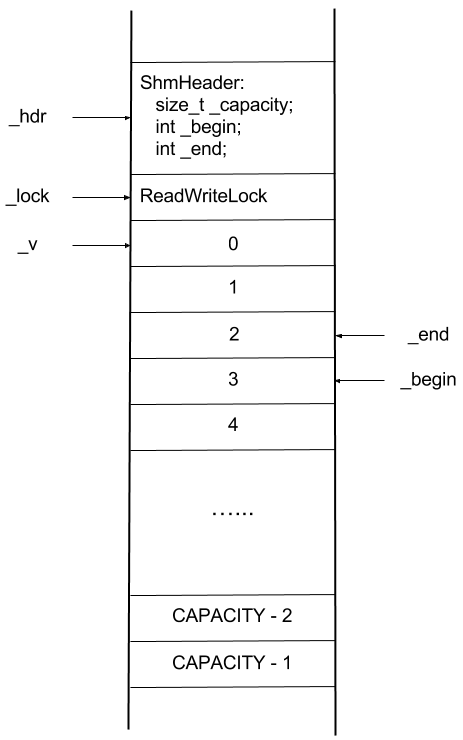
All of the data that need to be shared between processes are stored in the shared memory. The pointer _hdr points to the memory that contains the basic info of the ring buffer, e.g. capacity, beginning index and the ending index.
Following _hdr is the ReadWriteLock data structure. This R/W lock must be accessible by all processes that use this ring buffer, otherwise the pthread mutex and condition cannot work. And all the other memory left are used for the ring buffer.
The shared memory is created/opened in the constructor of ShmRingBuffer. Each process can define its own instance of ShmRingBuffer. The process to create the shared memory is master, and all other processes are slaves. The master process init pointers with the default values, while the slave processes init their pointers with the content of the shared memory.
Following is the code for ShmRingBuffer init.
template <typename T> inline bool
ShmRingBuffer<T>::init(size_t cap, bool master, const char * path)
{
assert(path != NULL);
int shm_fd = shm_open(path, O_CREAT | O_RDWR, S_IRWXU | S_IRWXG); // TODO: O_TRUNC?
if (shm_fd < 0) {
perror("shm_open failed");
return false;
}
_shm_size = sizeof(ShmHeader) + sizeof(ReadWriteLock) + cap * sizeof(T);
if (master && (ftruncate(shm_fd, _shm_size) < 0)) {
perror("ftruncate failed");
//shm_unlink(path);
//return false;
}
void *pbuf = NULL; /* shared memory adddress */
pbuf = mmap(NULL, _shm_size, PROT_READ | PROT_WRITE, MAP_SHARED, shm_fd, 0);
if (pbuf == (void *) -1) {
perror("mmap failed");
return false;
}
_hdr = reinterpret_cast<ShmHeader *>(pbuf);
assert(_hdr != NULL);
_lock = reinterpret_cast<ReadWriteLock *>((char*)_hdr + sizeof(ShmHeader));
assert(_lock != NULL);
_v = reinterpret_cast<T *>((char*)_lock + sizeof(ReadWriteLock));
assert(_v != NULL);
if (master) {
_hdr->_capacity = cap;
_hdr->_begin = _hdr->_end = 0;
_lock->init(true);
}
return true;
}
Test
In the test program test_shmringbuffer.cc, two processes are forked. The parent process inserts “2xxx” to the ring buffer, while the child process inserts “1xxx”. A sample output of this program is like:
boyang:shm_ring_buffer$ ./shmringbuf
......
parent: insert 2192, index 14
child: insert 1181, index 15
parent: insert 2193, index 17
child: insert 1182, index 17
child: insert 1183, index 18
parent: insert 2194, index 19
parent: insert 2195, index 0
child: insert 1184, index 1
parent: insert 2196, index 2
child: insert 1185, index 3
parent: insert 2197, index 4
child: insert 1186, index 5
parent: insert 2198, index 6
child: insert 1187, index 7
child: insert 1188, index 8
parent: insert 2199, index 9
child: insert 1189, index 10
child: insert 1190, index 11
child: insert 1191, index 12
child: insert 1192, index 13
child: insert 1193, index 14
Ring Buffer:
[0] 15: 2193
[0] 15: 1182
[0] 17: 1183
[0] 18: 2194
[0] 19: 2195
[0] 0: 1184
[0] 1: 2196
[0] 2: 1185
[0] 3: 2197
[0] 4: 1186
[0] 5: 2198
[0] 6: 1187
[0] 7: 1188
[0] 8: 2199
[0] 9: 1189
[0] 10: 1190
[0] 11: 1191
[0] 12: 1192
[0] 13: 1193
boyang:shm_ring_buffer$ child: insert 1194, index 15
child: insert 1195, index 16
child: insert 1196, index 17
child: insert 1197, index 18
child: insert 1198, index 19
child: insert 1199, index 0
In the above test, there’s a race condition when parent pushing 2193 and child inserting 1182. When formulating the log, the index of the ring buffer was still 15 - since a read/write lock is used, both parent and child can get the index 15. We can see that both parent and child successfully inserted their logs into the ring buffer.
When the parent process dumping the buffer, the child process hadn’t finished insertion yet. That’s why we can see 200 logs inserted from parent process, but only 193 logs inserted by the child process.
References
- Share condition variable & mutex between processes: does mutex have to locked before?
- pthread_mutexattr_getpshared, pthread_mutexattr_setpshared - get and set the process-shared attribute
- shm_open - open a shared memory object (REALTIME)
- std::is_pod
- What are Aggregates and PODs and how/why are they special?
- Wikipedia Circular buffer